さて、IN-MEMORY OLTP を試してみようと思う。
題材は「MAN+WOMAN=CHILD」
http://miko.org/~naruto/Artifact/MASKSQL.html
題材が「IN-MEMORY OLTP」の性能を測るのに適当かどうかは考えていない。
まずは通常のテーブルで試す。
Access 2003 (JET Database Engine)用の SQL だが、
文字列の結合がないのでそのまま SQL Server で動く。
さて、今度は MEMORY OPTIMIZED TABLE でやってみる。
まず、数のリストを持つテーブル「NumListM」を作成する。
数値に順序は関係ないので hash index にする。
今回はデータ数が 10固定なので BUCKET_COUNT として 10 を指定している。
実際には 2^n乗になるので 16 となる。
not null 制約は明示的に入れないとエラーになる。
また、PRIMARY KEY の既定は CLUSTERED だが、
MEMORY OPTIMIZED TABLE は Cluster化index はサポートしていないので
明示的に NONCLUSTERED を指定する。
作成した後は値を入れる
すでに元となる SQL文はあるので不要だが、
例をなぞって文字のリストのテーブルを作成する。
こっちもデータ数は固定なので BUCKET_COUNT として 10 を指定している。
実際には 2^n乗になるので 16 となる。
DB の照合順序が MEMORY OPTIMIZED TABLE でサポートされていないものの場合は
COLLATE文を用いて明示的に照合順序を指定する必要がある。
nchar型 ではなく、char型なのでコードページ1152 の照合順序である必要があり、
また index を付けるので BIN2 の照合順序である必要がある。
http://msdn.microsoft.com/ja-jp/library/dn133182(v=sql.120).aspx
同じく値を入れる
でも、CharListM は使わず、問題を解くクエリを作成し、実行するw。
力技のクエリ(テーブル10個を Cross Join) なのでちょっと時間(でも30秒かかっていなかった)がかかるが
Memory Optimized Table 使ったほうが通常のテーブル使う場合より 1.2倍速かった。
(具体的な数値を出したら怒られるよね?)
う~ん、もっと速くなると思っていたのだがなぁ。。。
って上記を最初に試したのは 12/23 だった。
今、ふと思い立ち、
「In-Memory OLTP White Paper」
http://download.microsoft.com/download/5/F/8/5F8D223F-E08B-41CC-8CE5-95B79908A872/SQL_Server_2014_In-Memory_OLTP_TDM_White_Paper.pdf
の「Native Compilation of Tables and Stored Procedures」のところを読んでみた。
(まだこの White Paper 全部読み終わってない)
あたりまえだけど、ストアドプロシージャにしないと Native Compile されないよね~(^^;
と、いうわけでストアドプロシージャ化。
schema binding するのに、Table の Schema名を明示しろと怒られたりした。
で、実行。
・・・(●_●)。
AdHoc で実行したときの 7倍、通常テーブルで実行したときの8倍くらいの速さ。
さすが Native Compile 機能。
これはおもしろかった。
---
2014年1月18日追記
ここから複写すると不等号が全角に成ったりするのでサンプルコードは下記から取得してください。
http://kazamai7610.wordpress.com/2014/01/03/%e3%80%8csql-server-2014-ctp2-%e3%82%92%e8%a9%a6%e3%81%97%e3%81%a6%e3%81%bf%e3%82%8b-3%e3%82%b9%e3%83%88%e3%82%a2%e3%83%89%e3%83%97%e3%83%ad%e3%82%b7%e3%83%bc%e3%82%b8%e3%83%a3%e3%81%ae-native-compi/
題材は「MAN+WOMAN=CHILD」
http://miko.org/~naruto/Artifact/MASKSQL.html
題材が「IN-MEMORY OLTP」の性能を測るのに適当かどうかは考えていない。
まずは通常のテーブルで試す。
Access 2003 (JET Database Engine)用の SQL だが、
文字列の結合がないのでそのまま SQL Server で動く。
さて、今度は MEMORY OPTIMIZED TABLE でやってみる。
まず、数のリストを持つテーブル「NumListM」を作成する。
CREATE TABLE NumListM(
num integer NOT NULL PRIMARY KEY NONCLUSTERED
HASH WITH (BUCKET_COUNT=10))
WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA );
数値に順序は関係ないので hash index にする。
今回はデータ数が 10固定なので BUCKET_COUNT として 10 を指定している。
実際には 2^n乗になるので 16 となる。
not null 制約は明示的に入れないとエラーになる。
また、PRIMARY KEY の既定は CLUSTERED だが、
MEMORY OPTIMIZED TABLE は Cluster化index はサポートしていないので
明示的に NONCLUSTERED を指定する。
作成した後は値を入れる
INSERT INTO NumListM(num) VALUES(0),(1),(2),(3),(4),(5),(6),(7),(8),(9);
すでに元となる SQL文はあるので不要だが、
例をなぞって文字のリストのテーブルを作成する。
CREATE TABLE dbo.CharListM(
c char(1) COLLATE Latin1_General_100_BIN2 NOT NULL
PRIMARY KEY
NONCLUSTERED
HASH WITH ( BUCKET_COUNT = 10))
WITH ( MEMORY_OPTIMIZED = ON , DURABILITY = SCHEMA_AND_DATA );
こっちもデータ数は固定なので BUCKET_COUNT として 10 を指定している。
実際には 2^n乗になるので 16 となる。
DB の照合順序が MEMORY OPTIMIZED TABLE でサポートされていないものの場合は
COLLATE文を用いて明示的に照合順序を指定する必要がある。
nchar型 ではなく、char型なのでコードページ1152 の照合順序である必要があり、
また index を付けるので BIN2 の照合順序である必要がある。
http://msdn.microsoft.com/ja-jp/library/dn133182(v=sql.120).aspx
同じく値を入れる
INSERT INTO CharListM(c) VALUES(’A’),(’C’),(’D’),(’H’),(’I’),(’L’),(’M’),(’N’),(’O’),(’W’);
でも、CharListM は使わず、問題を解くクエリを作成し、実行するw。
SELECT
(100 * M.num + 10 * A.num + N.num) AS MAN,
’+’ AS [PLUS],
(10000 * W.num + 1000 * O.num + 100 * M.num + 10 * A.num + N.num) AS WOMAN,
’=’ AS [EQUAL],
(10000 * C.num + 1000 * H.num + 100 * I.num + 10 * L.num + D.num) AS CHILD
FROM
NumListM AS A,
NumListM AS C,
NumListM AS D,
NumListM AS H,
NumListM AS I,
NumListM AS L,
NumListM AS M,
NumListM AS N,
NumListM AS O,
NumListM AS W
WHERE
((100 * M.num + 10 * A.num + N.num)
+ (10000 * W.num + 1000 * O.num + 100 * M.num + 10 * A.num + N.num)
= (10000 * C.num + 1000 * H.num + 100 * I.num + 10 * L.num + D.num))
AND (M.num>=1) AND (W.num >= 1) AND (C.num>=1)
AND (O.num W.num)
AND (M.num W.num)
AND (A.num W.num)
AND (N.num W.num)
AND (C.num W.num)
AND (H.num W.num)
AND (I.num W.num)
AND (L.num W.num)
AND (D.num W.num)
AND (M.num O.num)
AND (A.num O.num)
AND (N.num O.num)
AND (C.num O.num)
AND (H.num O.num)
AND (I.num O.num)
AND (L.num O.num)
AND (D.num O.num)
AND (A.num M.num)
AND (C.num M.num)
AND (H.num M.num)
AND (I.num M.num)
AND (L.num M.num)
AND (D.num M.num)
AND (M.num N.num)
AND (A.num N.num)
AND (C.num N.num)
AND (H.num N.num)
AND (I.num N.num)
AND (L.num N.num)
AND (D.num N.num)
AND (A.num C.num)
AND (A.num H.num)
AND (C.num H.num)
AND (D.num H.num)
AND (A.num I.num)
AND (C.num I.num)
AND (H.num I.num)
AND (D.num I.num)
AND (A.num L.num)
AND (C.num L.num)
AND (H.num L.num)
AND (I.num L.num)
AND (D.num L.num)
AND (A.num D.num)
AND (C.num D.num)
力技のクエリ(テーブル10個を Cross Join) なのでちょっと時間(でも30秒かかっていなかった)がかかるが
Memory Optimized Table 使ったほうが通常のテーブル使う場合より 1.2倍速かった。
(具体的な数値を出したら怒られるよね?)
う~ん、もっと速くなると思っていたのだがなぁ。。。
って上記を最初に試したのは 12/23 だった。
今、ふと思い立ち、
「In-Memory OLTP White Paper」
http://download.microsoft.com/download/5/F/8/5F8D223F-E08B-41CC-8CE5-95B79908A872/SQL_Server_2014_In-Memory_OLTP_TDM_White_Paper.pdf
の「Native Compilation of Tables and Stored Procedures」のところを読んでみた。
(まだこの White Paper 全部読み終わってない)
あたりまえだけど、ストアドプロシージャにしないと Native Compile されないよね~(^^;
と、いうわけでストアドプロシージャ化。
create procedure dbo.SoloveMask
with native_compilation, schemabinding, execute as owner
AS
BEGIN ATOMIC
with (transaction isolation level=snapshot, language=N’us_english’)
SELECT
(100 * M.num + 10 * A.num + N.num) AS MAN,
’+’ AS [PLUS],
(10000 * W.num + 1000 * O.num + 100 * M.num + 10 * A.num + N.num) AS WOMAN,
’=’ AS [EQUAL],
(10000 * C.num + 1000 * H.num + 100 * I.num + 10 * L.num + D.num) AS CHILD
FROM
dbo.NumListM AS A,
dbo.NumListM AS C,
dbo.NumListM AS D,
dbo.NumListM AS H,
dbo.NumListM AS I,
dbo.NumListM AS L,
dbo.NumListM AS M,
dbo.NumListM AS N,
dbo.NumListM AS O,
dbo.NumListM AS W
WHERE
((100 * M.num + 10 * A.num + N.num)
+ (10000 * W.num + 1000 * O.num + 100 * M.num + 10 * A.num + N.num)
= (10000 * C.num + 1000 * H.num + 100 * I.num + 10 * L.num + D.num))
AND (M.num>=1) AND (W.num >= 1) AND (C.num>=1)
AND (O.num W.num)
AND (M.num W.num)
AND (A.num W.num)
AND (N.num W.num)
AND (C.num W.num)
AND (H.num W.num)
AND (I.num W.num)
AND (L.num W.num)
AND (D.num W.num)
AND (M.num O.num)
AND (A.num O.num)
AND (N.num O.num)
AND (C.num O.num)
AND (H.num O.num)
AND (I.num O.num)
AND (L.num O.num)
AND (D.num O.num)
AND (A.num M.num)
AND (C.num M.num)
AND (H.num M.num)
AND (I.num M.num)
AND (L.num M.num)
AND (D.num M.num)
AND (M.num N.num)
AND (A.num N.num)
AND (C.num N.num)
AND (H.num N.num)
AND (I.num N.num)
AND (L.num N.num)
AND (D.num N.num)
AND (A.num C.num)
AND (A.num H.num)
AND (C.num H.num)
AND (D.num H.num)
AND (A.num I.num)
AND (C.num I.num)
AND (H.num I.num)
AND (D.num I.num)
AND (A.num L.num)
AND (C.num L.num)
AND (H.num L.num)
AND (I.num L.num)
AND (D.num L.num)
AND (A.num D.num)
AND (C.num D.num);
END;
schema binding するのに、Table の Schema名を明示しろと怒られたりした。
で、実行。
exec SoloveMask;
・・・(●_●)。
AdHoc で実行したときの 7倍、通常テーブルで実行したときの8倍くらいの速さ。
さすが Native Compile 機能。
これはおもしろかった。
---
2014年1月18日追記
ここから複写すると不等号が全角に成ったりするのでサンプルコードは下記から取得してください。
http://kazamai7610.wordpress.com/2014/01/03/%e3%80%8csql-server-2014-ctp2-%e3%82%92%e8%a9%a6%e3%81%97%e3%81%a6%e3%81%bf%e3%82%8b-3%e3%82%b9%e3%83%88%e3%82%a2%e3%83%89%e3%83%97%e3%83%ad%e3%82%b7%e3%83%bc%e3%82%b8%e3%83%a3%e3%81%ae-native-compi/
とりあえず、Windows Server 2012 の Hyper-V で Windows Server 2012 の Virtual Machine を作成した。
CPUは 1つ (増やし忘れた)、メモリは 4GBで。
そこに SQL Server 2014 CTP2 日本語版の ISOイメージからインストール。
特に引っかかることも無く終了。(設定をどうしたか忘れた)
そして SSMS 2014 CTP2 を立ち上げ、接続し、DBを作成する。
目的は In-Memory OLTP機能を試すことなので
「Memory Optimized Table」(メモリ最適化テーブル)対応の DBを作成する。
SSMS のオブジェクトエクスプローラーで「データベース」を右クリックして
「新しいデータベース」を選択する。
こうかなと思う設定をし、スクリプト出力して
「In-Memory OLTP White Paper」
http://download.microsoft.com/download/5/F/8/5F8D223F-E08B-41CC-8CE5-95B79908A872/SQL_Server_2014_In-Memory_OLTP_TDM_White_Paper.pdf
に書かれている SQL と比較したりしながら試行錯誤した結果、
「Memory Optimized Table」に対応させるには次のようにすることが分かった。
1. 通常のDBを作成するのと同様に設定する。
(後に文字列の「照合順序」の設定に注意しなければならないことが判明する。)
2. [ページの選択]で「ファイルグループ」を選択する。
[メモリ最適化データ]のラベルが付いた Grid があるので
そこに[ファイルグループの追加(I)]で
Memory Optimized Table用のファイルグループを追加する。
3. [ページの選択]で「全般」を選択する。
[追加(A)]でデータベースファイルを追加し、
「ファイルの種類」を「FILESTREAMデータ」にして
「ファイルグループ」でメモリ最適化データのファイルグループを選択する。
その他の項目は適正に設定する。
ここで、「Memory Optimized Table」では文字列の照合順序には次のような制限があることに注意する必要がある。
(1) (var)char型の照合順序はコードページ 1252 の照合順序を用いる必要がある。
nvarchar,nchar型はこの制限はない。
(2) (n)(var)char型の列に index を設定する場合は BIN2 照合順序にする必要がある。
http://msdn.microsoft.com/ja-jp/library/dn133182(v=sql.120).aspx
DB既定の照合順序を上記の条件を満たすもの以外にした場合は
「Memory Optimized Table」作成時に照合順序を COLLATE句で指定する必要が出てくる。
さて、DB を作ったので次は実際に動かしてみる。
CPUは 1つ (増やし忘れた)、メモリは 4GBで。
そこに SQL Server 2014 CTP2 日本語版の ISOイメージからインストール。
特に引っかかることも無く終了。(設定をどうしたか忘れた)
そして SSMS 2014 CTP2 を立ち上げ、接続し、DBを作成する。
目的は In-Memory OLTP機能を試すことなので
「Memory Optimized Table」(メモリ最適化テーブル)対応の DBを作成する。
SSMS のオブジェクトエクスプローラーで「データベース」を右クリックして
「新しいデータベース」を選択する。
こうかなと思う設定をし、スクリプト出力して
「In-Memory OLTP White Paper」
http://download.microsoft.com/download/5/F/8/5F8D223F-E08B-41CC-8CE5-95B79908A872/SQL_Server_2014_In-Memory_OLTP_TDM_White_Paper.pdf
に書かれている SQL と比較したりしながら試行錯誤した結果、
「Memory Optimized Table」に対応させるには次のようにすることが分かった。
1. 通常のDBを作成するのと同様に設定する。
(後に文字列の「照合順序」の設定に注意しなければならないことが判明する。)
2. [ページの選択]で「ファイルグループ」を選択する。
[メモリ最適化データ]のラベルが付いた Grid があるので
そこに[ファイルグループの追加(I)]で
Memory Optimized Table用のファイルグループを追加する。
3. [ページの選択]で「全般」を選択する。
[追加(A)]でデータベースファイルを追加し、
「ファイルの種類」を「FILESTREAMデータ」にして
「ファイルグループ」でメモリ最適化データのファイルグループを選択する。
その他の項目は適正に設定する。
ここで、「Memory Optimized Table」では文字列の照合順序には次のような制限があることに注意する必要がある。
(1) (var)char型の照合順序はコードページ 1252 の照合順序を用いる必要がある。
nvarchar,nchar型はこの制限はない。
(2) (n)(var)char型の列に index を設定する場合は BIN2 照合順序にする必要がある。
http://msdn.microsoft.com/ja-jp/library/dn133182(v=sql.120).aspx
DB既定の照合順序を上記の条件を満たすもの以外にした場合は
「Memory Optimized Table」作成時に照合順序を COLLATE句で指定する必要が出てくる。
さて、DB を作ったので次は実際に動かしてみる。
もともと、SQL Server 2012 R2 になるはずだったのが
SQL Server 2014 になるようになった。
現在はまだ CTP2 (Community Technology Preview 2)である。
で、新機能で興味深いのが In-Memory OLTP「HEKATON」である。
それを試しに触ってみたいと思った。
まず、SQL Server 2014 CTP2 の稼働環境を構築するにあたり、
稼働環境の要件を調べる。
「SQL Server 2014 CTP2」
http://www.microsoft.com/ja-jp/sqlserver/2014/default.aspx
のページから
「SQL Server 2014 データシート」
http://download.microsoft.com/download/9/8/0/980B9E8B-0147-4730-9AD1-964D06A7095A/SQL_Server_2014_Datasheet.pdf
をダウンロードし、その中の
「SQL Server 2014 をインストールするためのハードウェアおよびソフトウェア要件」のリンクを押す!・・・と SQL Server とは関係がないページに飛ばされます。(罠その1)
きっと SQL Server 2014 の稼働環境は MS のトップシークレットに違いない!!(大嘘)
あきらめて、英語の情報をさぐる。
「SQL Server 2014 CTP2」のページの「ja-jp」を「en-us」に変えてみる!
・・・がページが見つからないとのこと。
あきらめてググる。「SQL Server 2014 en-us」で。
すると「SQL Server 2014 CTP2」の英語のページにたどり着く。
http://www.microsoft.com/en-us/sqlserver/sql-server-2014.aspx
「SQL Server 2014 Datasheet」
http://download.microsoft.com/download/D/7/D/D7D64E12-C8E5-4A8C-A104-C945C188FA99/SQL_Server_2014_Datasheet.pdf
をダウンロードし、
「Hardware and Software Requirements for Installing SQL Server 2014」
のリンンくを押す!
・・・と今度は「Hardware and Software Requirements for Installing SQL Server 2012」
http://msdn.microsoft.com/en-us/library/ms143506.aspx
のページに飛ばされる。(罠その2)
やはり、 SQL Server 2014 の稼働環境は MS のトップシークレットに違いない!!(大嘘)
twitter で「SQL Server 2014 の稼働環境は MS のトップシークレット」と呟いたところ、
しばやんさん(http://shiba-yan.hatenablog.jp/about) に
「SQL Server 2014 のインストールに必要なハードウェアおよびソフトウェア」
http://msdn.microsoft.com/ja-jp/library/ms143506(v=sql.120).aspx
のページを教えてもらった。
つまり、MSDN Library で URL の「.aspx」の前に「(v=sql.120)」を入れると SQL Server 2014用の情報が表示されるのである。
先の「罠その2」でも URL の「.aspx」の前に「(v=sql.120)」を入れると
「Hardware and Software Requirements for Installing SQL Server 2014」
http://msdn.microsoft.com/en-us/library/ms143506(v=sql.120).aspx
にたどり着く。
こうして我々は MS のトップシークレットにたどり着いたのであった。(違)
SQL Server 2014 になるようになった。
現在はまだ CTP2 (Community Technology Preview 2)である。
で、新機能で興味深いのが In-Memory OLTP「HEKATON」である。
それを試しに触ってみたいと思った。
まず、SQL Server 2014 CTP2 の稼働環境を構築するにあたり、
稼働環境の要件を調べる。
「SQL Server 2014 CTP2」
http://www.microsoft.com/ja-jp/sqlserver/2014/default.aspx
のページから
「SQL Server 2014 データシート」
http://download.microsoft.com/download/9/8/0/980B9E8B-0147-4730-9AD1-964D06A7095A/SQL_Server_2014_Datasheet.pdf
をダウンロードし、その中の
「SQL Server 2014 をインストールするためのハードウェアおよびソフトウェア要件」のリンクを押す!・・・と SQL Server とは関係がないページに飛ばされます。(罠その1)
きっと SQL Server 2014 の稼働環境は MS のトップシークレットに違いない!!(大嘘)
あきらめて、英語の情報をさぐる。
「SQL Server 2014 CTP2」のページの「ja-jp」を「en-us」に変えてみる!
・・・がページが見つからないとのこと。
あきらめてググる。「SQL Server 2014 en-us」で。
すると「SQL Server 2014 CTP2」の英語のページにたどり着く。
http://www.microsoft.com/en-us/sqlserver/sql-server-2014.aspx
「SQL Server 2014 Datasheet」
http://download.microsoft.com/download/D/7/D/D7D64E12-C8E5-4A8C-A104-C945C188FA99/SQL_Server_2014_Datasheet.pdf
をダウンロードし、
「Hardware and Software Requirements for Installing SQL Server 2014」
のリンンくを押す!
・・・と今度は「Hardware and Software Requirements for Installing SQL Server 2012」
http://msdn.microsoft.com/en-us/library/ms143506.aspx
のページに飛ばされる。(罠その2)
やはり、 SQL Server 2014 の稼働環境は MS のトップシークレットに違いない!!(大嘘)
twitter で「SQL Server 2014 の稼働環境は MS のトップシークレット」と呟いたところ、
しばやんさん(http://shiba-yan.hatenablog.jp/about) に
「SQL Server 2014 のインストールに必要なハードウェアおよびソフトウェア」
http://msdn.microsoft.com/ja-jp/library/ms143506(v=sql.120).aspx
のページを教えてもらった。
つまり、MSDN Library で URL の「.aspx」の前に「(v=sql.120)」を入れると SQL Server 2014用の情報が表示されるのである。
先の「罠その2」でも URL の「.aspx」の前に「(v=sql.120)」を入れると
「Hardware and Software Requirements for Installing SQL Server 2014」
http://msdn.microsoft.com/en-us/library/ms143506(v=sql.120).aspx
にたどり着く。
こうして我々は MS のトップシークレットにたどり着いたのであった。(違)
外結合の on句に片一方のテーブルだけの条件を書く
2013年12月27日 コンピュータ内結合(内部結合 / INNER JOIN )のとき、WHERE条件に書く代わりにときどき ON句に条件を書くことがある。
これはまぁ問題無いはずで意図通りに動作する。
しかしながら、外結合(外部結合 / OUTER JOIN )の場合はどうなるか。
いまいち自信がなかったので試してみた。
試したのは SQL Server 2014 CTP2 で。
まず、テスト用のテーブル作成
で、値を突っ込む。
とりあえず、中身。
まず、ふつーに INNER JOIN と OUTER JOIN
さて、まず、LEFT OUTER JOIN で右だけの条件を追加する。
こんどは 左だけの条件を追加する。
今度は右外結合で結びつけている列とは関係ない列の条件で。
なぜこうなるのか?
「外部結合の使用」
http://technet.microsoft.com/ja-jp/library/ms187518.aspx
の説明では
とある。
その上で左外結合を説明すると
となる。
全外結合(完全外部結合) の場合で同様に考えると
は
となり、
は
のように CROSS JOIN と同様になる。
きちんと解ってしまえば迷うことが無いですね。
なお、実装が違うと動作が異なる可能性を否定できないのでご注意を。
これはまぁ問題無いはずで意図通りに動作する。
しかしながら、外結合(外部結合 / OUTER JOIN )の場合はどうなるか。
いまいち自信がなかったので試してみた。
試したのは SQL Server 2014 CTP2 で。
まず、テスト用のテーブル作成
CREATE TABLE T1 (F1 int);
CREATE TABLE T2 (G1 int,G2 int);
で、値を突っ込む。
INSERT INTO T1 VALUES(1),(2),(3),(4);
INSERT INTO T2 VALUES(1,1),(1,2),(2,1),(3,2),(5,3);
とりあえず、中身。
SELECT * FROM T1;
F1
-----------
1
2
3
4
SELECT * FROM T2;
G1 G2
----------- -----------
1 1
1 2
2 1
3 2
5 3
まず、ふつーに INNER JOIN と OUTER JOIN
SELECT F1,G1,G2
FROM T1 INNER JOIN T2 ON T1.F1 = T2.G1;
F1 G1 G2
----------- ----------- -----------
1 1 1
1 1 2
2 2 1
3 3 2
SELECT F1,G1,G2
FROM T1 LEFT OUTER JOIN T2 ON T1.F1 = T2.G1;
F1 G1 G2
----------- ----------- -----------
1 1 1
1 1 2
2 2 1
3 3 2
4 NULL NULL
SELECT F1,G1,G2
FROM T1 RIGHT OUTER JOIN T2 ON T1.F1 = T2.G1;
F1 G1 G2
----------- ----------- -----------
1 1 1
1 1 2
2 2 1
3 3 2
NULL 5 3
SELECT F1,G1,G2
FROM T1 FULL OUTER JOIN T2 ON T1.F1 = T2.G1;
F1 G1 G2
----------- ----------- -----------
1 1 1
1 1 2
2 2 1
3 3 2
4 NULL NULL
NULL 5 3
さて、まず、LEFT OUTER JOIN で右だけの条件を追加する。
SELECT F1,G1,G2
FROM T1 LEFT OUTER JOIN T2 ON T1.F1 = T2.G1 AND T2.G1 = 1;
F1 G1 G2
----------- ----------- -----------
1 1 1
1 1 2
2 NULL NULL
3 NULL NULL
4 NULL NULL
こんどは 左だけの条件を追加する。
SELECT F1,G1,G2
FROM T1 LEFT OUTER JOIN T2 ON T1.F1 = T2.G1 AND T1.F1 = 1;
F1 G1 G2
----------- ----------- -----------
1 1 1
1 1 2
2 NULL NULL
3 NULL NULL
4 NULL NULL
今度は右外結合で結びつけている列とは関係ない列の条件で。
SELECT F1,G1,G2
FROM T1 RIGHT OUTER JOIN T2 ON T1.F1 = T2.G1 AND T2.G2 = 2;
F1 G1 G2
----------- ----------- -----------
NULL 1 1
1 1 2
NULL 2 1
3 3 2
NULL 5 3
なぜこうなるのか?
「外部結合の使用」
http://technet.microsoft.com/ja-jp/library/ms187518.aspx
の説明では
「左外部結合の場合、参照される左側のテーブルからすべての行が取得されます」
とある。
その上で左外結合を説明すると
左のテーブルの各レコードに対し、
右のテーブルの各レコードと突き合わせて
ON句の条件が成立するものを結び付け、該当するものが無い場合には NULL にする
となる。
全外結合(完全外部結合) の場合で同様に考えると
SELECT F1,G1,G2
FROM T1 FULL OUTER JOIN T2 ON 1=0;
は
F1 G1 G2
----------- ----------- -----------
1 NULL NULL
2 NULL NULL
3 NULL NULL
4 NULL NULL
NULL 1 1
NULL 1 2
NULL 2 1
NULL 3 2
NULL 5 3
となり、
SELECT F1,G1,G2
FROM T1 FULL OUTER JOIN T2 ON 1=1;
は
F1 G1 G2
----------- ----------- -----------
1 1 1
1 1 2
1 2 1
1 3 2
1 5 3
2 1 1
2 1 2
2 2 1
2 3 2
2 5 3
3 1 1
3 1 2
3 2 1
3 3 2
3 5 3
4 1 1
4 1 2
4 2 1
4 3 2
4 5 3
のように CROSS JOIN と同様になる。
きちんと解ってしまえば迷うことが無いですね。
なお、実装が違うと動作が異なる可能性を否定できないのでご注意を。
今携わっている仕事は JAVA の仕事で既存の稼働中のシステムのサーバをベースにして新システム用のシステム用のサーバを開発するというものである。
まぁ基本的にそのまま持ってくるだけなのだが。
JAVA 6 + Tomcat 6 である。開発環境は Eclipse 3.5。
しかしこの仕事の前に JAVA を触ったことはほとんど無い。
それこそ 15年以上前にちょっと弄ってみたくらいである。
いやまぁこの仕事断ったら社内失業状態になるところだったんでやる以外の選択肢はなかったが。
まぁそれでもフレームワークをビルド出来るようになってソースを持って来れるようになればなんとかやれるようにはなった。
さて、今週は元のシステムに追加された機能をベースにした新機能の追加した。
なんやかんやで結構手を入れているので単純作業だけど時間は食った。
実装を終えてテスト用サーバで動かしてみた。
動かしている途中、ログを見ると「スレッド停止警告」と出ていた。あらら。
元のプログラムは直接スレッドを監視していなかったので起動したスレッドのオブジェクトを参照できるように拡張し、thread.getState() 出力するようにした。すると「Thread.State.BLOCKED」だった。
これは Deadlock が発生したな。
でもどこで起こっているのだろう。
で、再現させようと Eclipse でデバッグ実行。・・・・発生しない。
一晩放置で動かしたがデッドロックは発生しなかった。
テスト用のデータをソケットを介して流してくるテスト用サーバーからデータが流れてこないのが原因かと思い、ソケット受信するスレッドの代わりにダミーデータを送出するスレッドに置き換えたがやっぱり発生しない。
途方にくれてログに対して「BLOCKED」で grep をかけてみた。
・・・引っかかっているスレッド、今回追加した部分とは関係ないやつやん。あわわ。
無関係だと思って設定で起動しないようにしたスレッドを動かすようにしたら見事にログに BLOCKED と出てくるようになった。
BLOCK している状態で Eclipse の「デバッグ」ビューでそのスレッドを一時停止すると実行可能になったら次に実行する行を示して呼び出し階層が表示される。引っかかっているスレッドをすべて一時停止し、呼び出し階層をみて調べてみた。・・・・う~ん、なんで Deadlock になっているのかがわからん。Synchronized 付けたメソッドで互いに呼び出しあっているメソッドなんてないし。(そもそもこの時点で大きな勘違いをしている)。
いろいろ見て調べたが、最終的には「eclipse java debug deadlock」でググったときに出てくる
Stackoverflow の「 How to Debug a deadlock in Java using Eclipse」(http://stackoverflow.com/questions/2081766/how-to-debug-a-deadlock-in-java-using-eclipse)
を見て、
ことを知り、
「Jconsole Eclipse」でググって「Eclipseのtomcatプラグインから、jconsoleを利用する」(http://javastring.blog55.fc2.com/blog-entry-29.html) にたどり着いて
ことを知った。
「Eclipseのtomcatプラグインから、jconsoleを利用する」にある JAVA の起動パラメータを設定をして サーバーをデバッグ起動し、そして Jconsole を実行してみた・・・ら、ローカルでデバッグする場合は特に追加の JAVA起動パラメータを設定しなくても Jconsole が JVM に接続できることが分かったのでいったん終了し、追加した JVM起動パラメータを削除してもとに戻してサーバーをデバッグ起動し、Jconsole を起動して接続してみた。・・・おぉ、なんやグラフが表示される。
Jconsole でスレッドタブに移動する。「デッドロックを検出する」というボタンがある。押してみるとデッドロックしているスレッドの呼び出し階層とともに、ロックしている"もの"がロックした場所とともに表示された。
ロックしているものは「クラス名@16進数の数字」で表示されている。
で、まず、クラス名レベルで互いにロックしていることを確認し、数字も一致していることを確認した。・・・が、呼び出している synchronized メソッドは全然異なる。なんでだ?
そのとき閃いた。
はい、JAVA触って3か月目ですが、いまだきちんと学習していません。素人です。
調べたら 確かに JAVA で synchronized キーワードをメソッドにつけたらそのオブジェクトをロックするという意味だった。あとから考えたら、そしてよくあるロックの機構を考えたらそれが妥当であるし。
この前々日くらいに「いやぁ、こんなに synchronized 付けまくってたら同時実行性能が下がってしまいますよ。これ書いた人って分かって synchronized 付けているんですかね~」って軽口を叩いていたが、見事にブーメランの法則、「synchronized を分かっていないのはおれだぁ~。」である。(同時実行性能低下の問題があるのは確かなのですが)
オブジェクトがロックされていると分かれば問題となる個所もすぐにわかり、対応して無事 Deadlock が発生しなくなった。
やはり、慣れない言語に手をだすときは一通り言語の仕様を知るようにしましょう。思い込みは危険です。あうあうあう。
まぁ基本的にそのまま持ってくるだけなのだが。
JAVA 6 + Tomcat 6 である。開発環境は Eclipse 3.5。
しかしこの仕事の前に JAVA を触ったことはほとんど無い。
それこそ 15年以上前にちょっと弄ってみたくらいである。
いやまぁこの仕事断ったら社内失業状態になるところだったんでやる以外の選択肢はなかったが。
まぁそれでもフレームワークをビルド出来るようになってソースを持って来れるようになればなんとかやれるようにはなった。
さて、今週は元のシステムに追加された機能をベースにした新機能の追加した。
なんやかんやで結構手を入れているので単純作業だけど時間は食った。
実装を終えてテスト用サーバで動かしてみた。
動かしている途中、ログを見ると「スレッド停止警告」と出ていた。あらら。
元のプログラムは直接スレッドを監視していなかったので起動したスレッドのオブジェクトを参照できるように拡張し、thread.getState() 出力するようにした。すると「Thread.State.BLOCKED」だった。
これは Deadlock が発生したな。
でもどこで起こっているのだろう。
で、再現させようと Eclipse でデバッグ実行。・・・・発生しない。
一晩放置で動かしたがデッドロックは発生しなかった。
テスト用のデータをソケットを介して流してくるテスト用サーバーからデータが流れてこないのが原因かと思い、ソケット受信するスレッドの代わりにダミーデータを送出するスレッドに置き換えたがやっぱり発生しない。
途方にくれてログに対して「BLOCKED」で grep をかけてみた。
・・・引っかかっているスレッド、今回追加した部分とは関係ないやつやん。あわわ。
無関係だと思って設定で起動しないようにしたスレッドを動かすようにしたら見事にログに BLOCKED と出てくるようになった。
BLOCK している状態で Eclipse の「デバッグ」ビューでそのスレッドを一時停止すると実行可能になったら次に実行する行を示して呼び出し階層が表示される。引っかかっているスレッドをすべて一時停止し、呼び出し階層をみて調べてみた。・・・・う~ん、なんで Deadlock になっているのかがわからん。Synchronized 付けたメソッドで互いに呼び出しあっているメソッドなんてないし。(そもそもこの時点で大きな勘違いをしている)。
いろいろ見て調べたが、最終的には「eclipse java debug deadlock」でググったときに出てくる
Stackoverflow の「 How to Debug a deadlock in Java using Eclipse」(http://stackoverflow.com/questions/2081766/how-to-debug-a-deadlock-in-java-using-eclipse)
を見て、
「Jconsole」なるものがある
ことを知り、
「Jconsole Eclipse」でググって「Eclipseのtomcatプラグインから、jconsoleを利用する」(http://javastring.blog55.fc2.com/blog-entry-29.html) にたどり着いて
「JDK に Jconsole という JAVA アプリが含まれている」
ことを知った。
「Eclipseのtomcatプラグインから、jconsoleを利用する」にある JAVA の起動パラメータを設定をして サーバーをデバッグ起動し、そして Jconsole を実行してみた・・・ら、ローカルでデバッグする場合は特に追加の JAVA起動パラメータを設定しなくても Jconsole が JVM に接続できることが分かったのでいったん終了し、追加した JVM起動パラメータを削除してもとに戻してサーバーをデバッグ起動し、Jconsole を起動して接続してみた。・・・おぉ、なんやグラフが表示される。
Jconsole でスレッドタブに移動する。「デッドロックを検出する」というボタンがある。押してみるとデッドロックしているスレッドの呼び出し階層とともに、ロックしている"もの"がロックした場所とともに表示された。
ロックしているものは「クラス名@16進数の数字」で表示されている。
で、まず、クラス名レベルで互いにロックしていることを確認し、数字も一致していることを確認した。・・・が、呼び出している synchronized メソッドは全然異なる。なんでだ?
そのとき閃いた。
「もしかして、JAVA のメソッドに付けた synchronized キーワードってそのメソッドが呼び出されたらそのメソッドを持つオブジェクトをロックしているのか?」
はい、JAVA触って3か月目ですが、いまだきちんと学習していません。素人です。
調べたら 確かに JAVA で synchronized キーワードをメソッドにつけたらそのオブジェクトをロックするという意味だった。あとから考えたら、そしてよくあるロックの機構を考えたらそれが妥当であるし。
この前々日くらいに「いやぁ、こんなに synchronized 付けまくってたら同時実行性能が下がってしまいますよ。これ書いた人って分かって synchronized 付けているんですかね~」って軽口を叩いていたが、見事にブーメランの法則、「synchronized を分かっていないのはおれだぁ~。」である。(同時実行性能低下の問題があるのは確かなのですが)
オブジェクトがロックされていると分かれば問題となる個所もすぐにわかり、対応して無事 Deadlock が発生しなくなった。
やはり、慣れない言語に手をだすときは一通り言語の仕様を知るようにしましょう。思い込みは危険です。あうあうあう。
低速なネットワークと仮想スイッチをつないだ環境でのVMのDC構築のトラブル
2012年12月30日 コンピュータ会社で開発に使っているタワー機は Windows Server で Hyper-V を動かし、実際の開発環境はその VM上に用意している。
仮想VM の中に開発環境用のドメインコントローラー(DC)を用意して基本的に開発環境はそのドメインを使っている。
が、ホスト機のドメインはホスト機内部ドメインともまた会社のドメインとも別にしたかったので USB-Ethernet Adapter を利用して 古い32bitノートパソコンに Windows Server 2008 を入れて DC としていた。
仮想スイッチは
• ホスト内部
• 会社のネットワークにつなげたもの
• USB-Ethernet Adapter につなげたもの
の3つ。
ホスト機のドメインで、ホスト機内部のドメインを「信頼できるドメイン」とし、ホスト機をいじるときもホスト機内部のドメインのアカウントでログインしていた。
当初はホスト機は Windows Server 2008R2 だったが、Windows Server 2012 にアップグレードした。
そのころからか、ホスト機へのログインに時間がかかるようになった。リモートデスクトップで接続しようとしても「ローカルセッションマネージャの準備をしています」としばらく出てそのまま切断されてしまうとか。
耐えられなくなったのでホスト機のドメインのDC を仮想環境内に作ることにした。多分そうすれば改善するだろうと。
折角なので Windows Server 2012 を使うことにした。
VM を作成し、USB-Ethernet Adapter に接続したネットワークに接続した。
で、Active Directory をインストールし、設定を行う。
しかし、どうしてもエラーが出る。
調べたが特に情報はみつからない。
Windows Update で最新にしても同じエラー。
一旦ドメインに参加させてからやっても同じ。
Windows Server 2012 の ISOイメージの Supportディレクトリに入っているADPREPを利用してあらかじめスキーマのアップグレードをしようとしてみたが、その ADPREP は64bit にしか対応しておらず、動かなかった。
GUI のウィザードで生成されたコマンドを PowerShell でもやってみたが同じエラー。
途中が USB-Ethernet Adapter というのが原因かと思い、横で ping を飛ばし続けて観察する。
するとフォレストのアップグレードと出ているときに一時 ping が通らなくなることがわかった。
ドメインコントローラの通信は低速な回線でも使えるはずなので VM のネットワークの最大帯域幅を 5Mbps に制限してみた。
すると、ping でたまに届かないことはあったものの、今度は無事DCを構築することができた。
ホスト機へのログインは早くなったような気がするがもうしばらく様子は見る。
仮想VM の中に開発環境用のドメインコントローラー(DC)を用意して基本的に開発環境はそのドメインを使っている。
が、ホスト機のドメインはホスト機内部ドメインともまた会社のドメインとも別にしたかったので USB-Ethernet Adapter を利用して 古い32bitノートパソコンに Windows Server 2008 を入れて DC としていた。
仮想スイッチは
• ホスト内部
• 会社のネットワークにつなげたもの
• USB-Ethernet Adapter につなげたもの
の3つ。
ホスト機のドメインで、ホスト機内部のドメインを「信頼できるドメイン」とし、ホスト機をいじるときもホスト機内部のドメインのアカウントでログインしていた。
当初はホスト機は Windows Server 2008R2 だったが、Windows Server 2012 にアップグレードした。
そのころからか、ホスト機へのログインに時間がかかるようになった。リモートデスクトップで接続しようとしても「ローカルセッションマネージャの準備をしています」としばらく出てそのまま切断されてしまうとか。
耐えられなくなったのでホスト機のドメインのDC を仮想環境内に作ることにした。多分そうすれば改善するだろうと。
折角なので Windows Server 2012 を使うことにした。
VM を作成し、USB-Ethernet Adapter に接続したネットワークに接続した。
で、Active Directory をインストールし、設定を行う。
しかし、どうしてもエラーが出る。
ADPrep 実行の失敗 --> System.ComponentModel.Win32Exception (0x80004005): システムに接続されたデバイスが機能していません。
調べたが特に情報はみつからない。
Windows Update で最新にしても同じエラー。
一旦ドメインに参加させてからやっても同じ。
Windows Server 2012 の ISOイメージの Supportディレクトリに入っているADPREPを利用してあらかじめスキーマのアップグレードをしようとしてみたが、その ADPREP は64bit にしか対応しておらず、動かなかった。
GUI のウィザードで生成されたコマンドを PowerShell でもやってみたが同じエラー。
途中が USB-Ethernet Adapter というのが原因かと思い、横で ping を飛ばし続けて観察する。
するとフォレストのアップグレードと出ているときに一時 ping が通らなくなることがわかった。
ドメインコントローラの通信は低速な回線でも使えるはずなので VM のネットワークの最大帯域幅を 5Mbps に制限してみた。
すると、ping でたまに届かないことはあったものの、今度は無事DCを構築することができた。
ホスト機へのログインは早くなったような気がするがもうしばらく様子は見る。
Oracle Database のセットアップで苦戦
2012年10月28日 コンピュータOracle Database 10.2.0.4.0 を Windows Server 2008 の VM 2台にインストールした。
1台は DB の作成まで行い、もう一台はインストールのみで DB まではインストールせず。
目的は Data Guard を試すこと。
テスト用ネットワークと社内LAN との両方につなげていたせいが Enterprise Manager のセットアップに失敗して起動せず苦労したがなんとか修復した。
(
http://faizsulaiman.com/unable-to-determine-local-host-from-url-repository_url/
を参考にして復旧した。
コマンドラインを管理者モードで起動していなかったとか
環境変数としてOracle_Home が設定されていなかったから失敗したとか。
Oracle に含まれる証明書が古いせいで enterprise manager が設定後に起動せず、
emctl unsecure dbconsole
として起動するようになったとか。
)
しかしながら、SQL PLUS から接続できないという現象に苦戦した。
正確には、ローカルから接続できるが、ローカル及びもう一台から TNSサービス名を指定すると接続できないという現象である。
Oracle Net Manager でいろいろいじったり、
Database の Service Name を確認したり(※1 この時点でいじった記憶はないが、いじったとしか思えない事象が出てくる)、
したが改善せず。
で、TNSNAMES ではなく、EZCONNECT でつなげてみる・・・とあっさりつながった。(でもこれ自体がおかしいということがわかり、※1 でいじったとしか思えない)
どうしても理由がわからず、別の機械に Oracle 11.2 の Instant Client を Install して接続してみたら EZCONNECT でも TNSNAMES でもつながった。
tnsnames.ora は同じにしたのに。
この問題、2週間くらい解決せず。
で、昨日もいじっていて、試しに instant client では使っていない sqlnet.ora をリネームしてみた。
・・・そしたらあっさり接続できた。
sqlnet.ora の中身を一行づつコメントアウトして試したら
NAMES.DEFAULT_DOMAIN
が原因だと判明した。
これが設定されている場合、SQL PLUS で TNSサービス名を指定した時にその TNSサービス名が「.」を付けていなかったら
NAMES.DEFAULT_DOMAIN の設定文字列を付けるというものである。
つまり、tnsnames.ora でのTNSサービス名に予め NAMES.DEFAULT_DOMAIN を付与している必要があるのである。(あるいは、 NAMES.DEFAULT_DOMAIN を設定しないか.)
(
http://otndnld.oracle.co.jp/document/products/oracle10g/102/doc_cd/network.102/B19209-01/sqlnet.htm
)
さて、これで問題解決・・・では終わらなかった。
SERVICE_NAME をいろいろいじっていて
「.」を含むサービス名にしたときは接続できるが、「.」を含まない場合は接続できない。
という現象に出くわした。
調べてみたが、「.」を付けない名前にしたときは DB_DOMAIN の設定値が付加されるとのこと。
LSNRCTL で Services を見ても DOMAIN名が付与されている。
なのに EZCONNECT でDB_DOMAIN が付いたサービス名を指定しても接続できない。
半日なやんでふと気が付いた。
DB_DOMAIN の設定しているドメイン名で綴り間違いをしていた。
間違った綴りで EZCONNECT で接続もできた。
で、 DB_DOMAIN と Global_NAME を変更した。
(
http://docs.oracle.com/cd/B19306_01/server.102/b14231/ds_admin.htm
)
これでいいか・・・と思ったがふと気になって Enterprise Manager を見てみたら DB に接続できていない。
Enterprise Manager の再設定をしなおした。
(
(環境変数 ORACLE_SID は設定済だとして)
管理者モードのコマンドラインから
環境変数 ORALCE_HOMENAME の設定して
emca -deconfig dbconsole db
emca -config dbconsole db
(※設定後の起動に失敗する)
emctl unsecure dbconsole
emctl start dbconsole
)
これでやっと準備ができた。
1台は DB の作成まで行い、もう一台はインストールのみで DB まではインストールせず。
目的は Data Guard を試すこと。
テスト用ネットワークと社内LAN との両方につなげていたせいが Enterprise Manager のセットアップに失敗して起動せず苦労したがなんとか修復した。
(
http://faizsulaiman.com/unable-to-determine-local-host-from-url-repository_url/
を参考にして復旧した。
コマンドラインを管理者モードで起動していなかったとか
環境変数としてOracle_Home が設定されていなかったから失敗したとか。
Oracle に含まれる証明書が古いせいで enterprise manager が設定後に起動せず、
emctl unsecure dbconsole
として起動するようになったとか。
)
しかしながら、SQL PLUS から接続できないという現象に苦戦した。
正確には、ローカルから接続できるが、ローカル及びもう一台から TNSサービス名を指定すると接続できないという現象である。
Oracle Net Manager でいろいろいじったり、
Database の Service Name を確認したり(※1 この時点でいじった記憶はないが、いじったとしか思えない事象が出てくる)、
したが改善せず。
で、TNSNAMES ではなく、EZCONNECT でつなげてみる・・・とあっさりつながった。(でもこれ自体がおかしいということがわかり、※1 でいじったとしか思えない)
どうしても理由がわからず、別の機械に Oracle 11.2 の Instant Client を Install して接続してみたら EZCONNECT でも TNSNAMES でもつながった。
tnsnames.ora は同じにしたのに。
この問題、2週間くらい解決せず。
で、昨日もいじっていて、試しに instant client では使っていない sqlnet.ora をリネームしてみた。
・・・そしたらあっさり接続できた。
sqlnet.ora の中身を一行づつコメントアウトして試したら
NAMES.DEFAULT_DOMAIN
が原因だと判明した。
これが設定されている場合、SQL PLUS で TNSサービス名を指定した時にその TNSサービス名が「.」を付けていなかったら
NAMES.DEFAULT_DOMAIN の設定文字列を付けるというものである。
つまり、tnsnames.ora でのTNSサービス名に予め NAMES.DEFAULT_DOMAIN を付与している必要があるのである。(あるいは、 NAMES.DEFAULT_DOMAIN を設定しないか.)
(
http://otndnld.oracle.co.jp/document/products/oracle10g/102/doc_cd/network.102/B19209-01/sqlnet.htm
)
さて、これで問題解決・・・では終わらなかった。
SERVICE_NAME をいろいろいじっていて
「.」を含むサービス名にしたときは接続できるが、「.」を含まない場合は接続できない。
という現象に出くわした。
調べてみたが、「.」を付けない名前にしたときは DB_DOMAIN の設定値が付加されるとのこと。
LSNRCTL で Services を見ても DOMAIN名が付与されている。
なのに EZCONNECT でDB_DOMAIN が付いたサービス名を指定しても接続できない。
半日なやんでふと気が付いた。
DB_DOMAIN の設定しているドメイン名で綴り間違いをしていた。
間違った綴りで EZCONNECT で接続もできた。
で、 DB_DOMAIN と Global_NAME を変更した。
(
http://docs.oracle.com/cd/B19306_01/server.102/b14231/ds_admin.htm
)
これでいいか・・・と思ったがふと気になって Enterprise Manager を見てみたら DB に接続できていない。
Enterprise Manager の再設定をしなおした。
(
(環境変数 ORACLE_SID は設定済だとして)
管理者モードのコマンドラインから
環境変数 ORALCE_HOMENAME の設定して
emca -deconfig dbconsole db
emca -config dbconsole db
(※設定後の起動に失敗する)
emctl unsecure dbconsole
emctl start dbconsole
)
これでやっと準備ができた。

・秋月電子:DCプラグ変換プラグ(2.1mm[メス]⇒2.5mm[オス]変換)
[DC-9223]
http://akizukidenshi.com/catalog/g/gC-00179/
・マルツー:【MA-122SL】L型変換プラグ 2.5φプラグ用
http://www.marutsu.co.jp/shohin_40978/
を買ってきました。
---
2.1mm->2.5mm の変換アダプタ無くした><
http://10395.diarynote.jp/201201310654212993/
LB-L201BR のための ACアダプター調達
http://10395.diarynote.jp/201108312154063708/
2.1mm->2.5mm の変換アダプタ無くした><
2012年1月31日 コンピュータACアダプター を先日の VSUG のために
会社 -> 会場 -> 家-> 会社
と持ち歩いた。そしたら先に付けていた 2.1mm->2.5mm の変換アダプタが無くなっていた><
一緒にその先に着けていた I字->L字変換アダプタも。
あうあうあう。
また秋葉原に買いに行かないと。
---
LB-L201BR のための ACアダプター調達
http://10395.diarynote.jp/201108312154063708/
再度調達!!
http://10395.diarynote.jp/201202041840265290/
会社 -> 会場 -> 家-> 会社
と持ち歩いた。そしたら先に付けていた 2.1mm->2.5mm の変換アダプタが無くなっていた><
一緒にその先に着けていた I字->L字変換アダプタも。
あうあうあう。
また秋葉原に買いに行かないと。
---
LB-L201BR のための ACアダプター調達
http://10395.diarynote.jp/201108312154063708/
再度調達!!
http://10395.diarynote.jp/201202041840265290/
Windows Phone用アプリ「十二支から年齢」
2012年1月15日 コンピュータ 昨年12月10日に行われた Windows Phone ハッカソンに参加した。
AppHub のアカウントをタダでもらえるというので。
その時はグループでアプリを作成したが僕はリソース探し等でプログラミングはしなかった。
また、AppHub のアカウントをタダでくれる条件がアプリを作成してMarket Place に申請するというものだったが、サンプルのアプリを加工してダミーアプリ作って登録するように言われたのでそのとおりやってみた。
ただ、タダでアカウントもらったんだから、ダミーだけではなく、なんか作って MarketPlace に申請しておかないとなぁ。。。っってことがあり、また「Windows Phone Holiday Apps コンテスト」で「年末年始」を題材にしたアプリのコンテストの募集をしていたので 12/15 の香港へ行く日にかけてアプリ「EtoEto」を作成し、コンテストへの応募とあたらしいアプリの申請を行った。
そのときに 12/10 のハッカソンで登録申請したダミーアプリが審査におちていたことが判明。 SnapShot にデバッグ用の情報が表示されていたために却下された。
香港で Simロックフリーの Windows Phone機「NOKIA Lumia 710」を購入し、12/18 に日本に持ち帰った。もしかしたらそのときは国内では最初の「NOKIA Lumia 710」だったかもしれない。
12/20 の Windows Phone ハッカソンの当日会場で AppHub を見ていたら今度は Holiday Apps コンテストに応募したプログラムが MarketPlace の審査で却下されてた。理由は「メッセージボックス等が表示されているときに後ろの画面を操作できてはいけない」というルールに反していたからだった。・・・そんなルール、知らなかったよ。
で、12/20 の Windows Phone ハッカソンで開始時に、「申請前に最低 『MarketPlace TestKit』で確認するように」と言われた。「MarketPlace TestKit」? どっかで聞いたことがあるような気はするが、なにそれ?
とりあえず、アプリを一本なんとか作成した後に「MarketPlace TestKit」をググってしらべてみた。どこで手に入れるものかよくわからない~って探していたら
「Visual Studio 2010」の「プロジェクト」メニュー内にいつの間にか項目ができていることが判明。しらなかった・・・というより、知らないで応募したらそりゃ申請で却下されるわなと。
その時作ったのプログラムもその「MarketPlace TestKit」の手動テストの項目と照らし合わせて「却下」判定になったので申請は見合わせた。
年が明けて時間に余裕ができて申請が却下されたアプリ「EtoEto」を大きく見直し、またアプリ名が「Windows Phone Holiday Apps コンテスト」で賞を取ったアプリと名称がかぶっていたので名前を変えて申請した。今回はちゃんと「MarketPlace TestKit」でセルフテストをしてから申請を出した。
申請を通過したらそのまま公開するようにしていたらいつの間にか公開されていた。
これが「十二支から年齢」である。
http://www.windowsphone.com/ja-JP/apps/608d955c-30e2-47ba-b273-c094f724d729
アプリを公開したのは久しぶり。
ただし、公開されてから5日ほど経つようだがダウンロード数はまだ一桁である。
次は 12/20 のWPハッカソンで作ったプログラムをブラッシュアップして公開する予定。
AppHub のアカウントをタダでもらえるというので。
その時はグループでアプリを作成したが僕はリソース探し等でプログラミングはしなかった。
また、AppHub のアカウントをタダでくれる条件がアプリを作成してMarket Place に申請するというものだったが、サンプルのアプリを加工してダミーアプリ作って登録するように言われたのでそのとおりやってみた。
ただ、タダでアカウントもらったんだから、ダミーだけではなく、なんか作って MarketPlace に申請しておかないとなぁ。。。っってことがあり、また「Windows Phone Holiday Apps コンテスト」で「年末年始」を題材にしたアプリのコンテストの募集をしていたので 12/15 の香港へ行く日にかけてアプリ「EtoEto」を作成し、コンテストへの応募とあたらしいアプリの申請を行った。
そのときに 12/10 のハッカソンで登録申請したダミーアプリが審査におちていたことが判明。 SnapShot にデバッグ用の情報が表示されていたために却下された。
香港で Simロックフリーの Windows Phone機「NOKIA Lumia 710」を購入し、12/18 に日本に持ち帰った。もしかしたらそのときは国内では最初の「NOKIA Lumia 710」だったかもしれない。
12/20 の Windows Phone ハッカソンの当日会場で AppHub を見ていたら今度は Holiday Apps コンテストに応募したプログラムが MarketPlace の審査で却下されてた。理由は「メッセージボックス等が表示されているときに後ろの画面を操作できてはいけない」というルールに反していたからだった。・・・そんなルール、知らなかったよ。
で、12/20 の Windows Phone ハッカソンで開始時に、「申請前に最低 『MarketPlace TestKit』で確認するように」と言われた。「MarketPlace TestKit」? どっかで聞いたことがあるような気はするが、なにそれ?
とりあえず、アプリを一本なんとか作成した後に「MarketPlace TestKit」をググってしらべてみた。どこで手に入れるものかよくわからない~って探していたら
「Visual Studio 2010」の「プロジェクト」メニュー内にいつの間にか項目ができていることが判明。しらなかった・・・というより、知らないで応募したらそりゃ申請で却下されるわなと。
その時作ったのプログラムもその「MarketPlace TestKit」の手動テストの項目と照らし合わせて「却下」判定になったので申請は見合わせた。
年が明けて時間に余裕ができて申請が却下されたアプリ「EtoEto」を大きく見直し、またアプリ名が「Windows Phone Holiday Apps コンテスト」で賞を取ったアプリと名称がかぶっていたので名前を変えて申請した。今回はちゃんと「MarketPlace TestKit」でセルフテストをしてから申請を出した。
申請を通過したらそのまま公開するようにしていたらいつの間にか公開されていた。
これが「十二支から年齢」である。
http://www.windowsphone.com/ja-JP/apps/608d955c-30e2-47ba-b273-c094f724d729
アプリを公開したのは久しぶり。
ただし、公開されてから5日ほど経つようだがダウンロード数はまだ一桁である。
次は 12/20 のWPハッカソンで作ったプログラムをブラッシュアップして公開する予定。
SQL Server の Cast と Convert に関する考察
2011年10月28日 コンピュータアクセスログ見ていると、
http://10395.diarynote.jp/200408300855070000/
がトラップになって
での検索のアクセスがあった。
次のコードで実験。
(コピーする場合は下記から。
http://kazamai7610.wordpress.com/2011/10/27/cast-%e3%81%a8-convert-%e3%81%ae%e6%a4%9c%e8%a8%bc/
)
結果
つまり、Dafault制約で Cast を使ったにもかかわらず、
その制約を確認すると Convert に書き換わっているわけです。
このことは SQL Server Management Studio (SSMS) からも確認できます。
というわけで、内部的には Cast は Convert に置き換えられるようです。
したがって、
というのが僕の意見です。
・・・もちろん、引数の数からして違うので convert の方が多彩な動きがあるのですが。
(
Convert の引数による動作の違いは
http://msdn.microsoft.com/ja-jp/library/ms187928.aspx
を参照。)
---
2013年4月12日追記
所謂「糖衣構文(Syntactic sugar)」ってやつですね。
http://ja.wikipedia.org/wiki/%E7%B3%96%E8%A1%A3%E6%A7%8B%E6%96%87
リファレンスマニュアルで同一項目に書いてあるのも同じものだからでしょう。
---
2013年12月20日追記
歴史的経緯を補足するならば、もともとは convert だけだったが
ANSI SQL に準拠するためにあとから cast が追加されたってことです。
---
2015年2月8日追記
速さを気にしての検索を見受けられるが、Where句でキャスト(型変換の意。暗黙、明示的な Cast,Convertの利用すべて)するとインデックスとかが利かなくなるのでそもそもキャスト自体を避けるべき。
日時絡みなら
http://10395.diarynote.jp/201008270101429723
の余談が参考になるかも。
http://10395.diarynote.jp/200408300855070000/
がトラップになって
「sql castとconvertの違い」
での検索のアクセスがあった。
次のコードで実験。
CREATE TABLE test2 (
a date
CONSTRAINT DF_test2__a DEFAULT CAST(’10-1-10’ as date)
, b float
CONSTRAINT DF_test2__b DEFAULT CAST(2 as float)
)
SELECT
C.name
, D.definition as default_constraint
FROM
sys.default_constraints D
INNER JOIN sys.columns C
ON D.object_id=C.default_object_id
WHERE C.object_id = object_id(’test2’)
(コピーする場合は下記から。
http://kazamai7610.wordpress.com/2011/10/27/cast-%e3%81%a8-convert-%e3%81%ae%e6%a4%9c%e8%a8%bc/
)
結果
name | default_constraint
a | (CONVERT([date],’10-1-10’,0))
b | (CONVERT([float],(2),0))
つまり、Dafault制約で Cast を使ったにもかかわらず、
その制約を確認すると Convert に書き換わっているわけです。
このことは SQL Server Management Studio (SSMS) からも確認できます。
というわけで、内部的には Cast は Convert に置き換えられるようです。
したがって、
Cast と Convert は気にするような違いは無い
というのが僕の意見です。
・・・もちろん、引数の数からして違うので convert の方が多彩な動きがあるのですが。
(
Convert の引数による動作の違いは
http://msdn.microsoft.com/ja-jp/library/ms187928.aspx
を参照。)
---
2013年4月12日追記
所謂「糖衣構文(Syntactic sugar)」ってやつですね。
http://ja.wikipedia.org/wiki/%E7%B3%96%E8%A1%A3%E6%A7%8B%E6%96%87
リファレンスマニュアルで同一項目に書いてあるのも同じものだからでしょう。
---
2013年12月20日追記
歴史的経緯を補足するならば、もともとは convert だけだったが
ANSI SQL に準拠するためにあとから cast が追加されたってことです。
---
2015年2月8日追記
速さを気にしての検索を見受けられるが、Where句でキャスト(型変換の意。暗黙、明示的な Cast,Convertの利用すべて)するとインデックスとかが利かなくなるのでそもそもキャスト自体を避けるべき。
日時絡みなら
http://10395.diarynote.jp/201008270101429723
の余談が参考になるかも。
LB-L201BR のための ACアダプター調達
2011年8月31日 コンピュータLB-L201BR を持ち歩くときに ACアダプターも一緒に持ち歩いていた。比較的軽量なものなのだが、会社に持って行ってうっかり持って帰るのを忘れたり、家から会社へ持っていくのを忘れたりしたら困る。そういうわけで ACアダプターの調達を検討。
まず、マウスコンピューターのページへ。ACアダプター、参考価格が「10290円」と書いてある。この時点で純正あきらめた。
LB-L201BRのACアダプターは出力 19.5V 3.42A 65W でジャックは 内径2.5mmである。同じものだったら使えるはずだ。
さて、秋葉原で物色。秋月電子に行ってみた。
出力が合致するものがあったが、ジャックの内径が 2.1mm のものしかない。残念。
あきらめて他の店や中古も物色したが適切なものは見つからなかった。
その後のある日、秋月電子のWEBのショップを見ていると、「2.1mm->2.5mm変換アダプタ」なるものがあることが判明した。
なるほど、先の ACアダプタに変換アダプタをつければいいのか。
そういうわけで再度秋月電子へ。
店の中を探したが、該当の変換アダプタはみつからず、レジの店員さんに聞いたらそのレジのところにあった。
そういうわけで ACアダプタ 1700円と変換アダプタ60円を購入した。
これで会社に行くときには ACアダプタを持ち歩く必要はなくなった。
めでたし。
・・・・しばらくしてふと「I型をL型に変換するアダプタは無いのかな?」と思った。妙に出っ張るので。
ググってみると物はあった。マルツーパーツショップにあり、店舗が秋葉原にもある。
そういうわけで秋葉原に行って物をゲット。90円。
とりあえず、問題なく使えています。
---
2.1mm->2.5mm の変換アダプタ無くした><
http://10395.diarynote.jp/201201310654212993/
再度調達!!
http://10395.diarynote.jp/201202041840265290/
まず、マウスコンピューターのページへ。ACアダプター、参考価格が「10290円」と書いてある。この時点で純正あきらめた。
LB-L201BRのACアダプターは出力 19.5V 3.42A 65W でジャックは 内径2.5mmである。同じものだったら使えるはずだ。
さて、秋葉原で物色。秋月電子に行ってみた。
出力が合致するものがあったが、ジャックの内径が 2.1mm のものしかない。残念。
あきらめて他の店や中古も物色したが適切なものは見つからなかった。
その後のある日、秋月電子のWEBのショップを見ていると、「2.1mm->2.5mm変換アダプタ」なるものがあることが判明した。
なるほど、先の ACアダプタに変換アダプタをつければいいのか。
そういうわけで再度秋月電子へ。
店の中を探したが、該当の変換アダプタはみつからず、レジの店員さんに聞いたらそのレジのところにあった。
そういうわけで ACアダプタ 1700円と変換アダプタ60円を購入した。
これで会社に行くときには ACアダプタを持ち歩く必要はなくなった。
めでたし。
・・・・しばらくしてふと「I型をL型に変換するアダプタは無いのかな?」と思った。妙に出っ張るので。
ググってみると物はあった。マルツーパーツショップにあり、店舗が秋葉原にもある。
そういうわけで秋葉原に行って物をゲット。90円。
とりあえず、問題なく使えています。
---
2.1mm->2.5mm の変換アダプタ無くした><
http://10395.diarynote.jp/201201310654212993/
再度調達!!
http://10395.diarynote.jp/201202041840265290/
土曜日に腰を痛めました。
トイレで洋式便所から立ち上がり、少しして違和感。
翌日にはすごく痛くなり、医者に行きました。
診断結果は急性腰痛。いわゆるぎっくり腰です。
移動の時にはコルセットを着けています。
トイレで洋式便所から立ち上がり、少しして違和感。
翌日にはすごく痛くなり、医者に行きました。
診断結果は急性腰痛。いわゆるぎっくり腰です。
移動の時にはコルセットを着けています。


仕方が無いのでヨドバシに UQ WIMax のルーターを買いに行った。
すると、WiMaxルーターといっしょにパソコンを買うと3000円割り引かれるというキャンペーンをしていた。
で、店頭で散々悩んだが決められず。
一休みに喫茶店に入り、マウスコンピューターでの販売価格を調べてみた。
すると、なんと、WiMaxルーター込で 1万円割引のキャンペーンをやっていた。
そこで 「LB-L201 BR」 の 「OS無し」を購入した。
送料・割引込みで 11.3インチ Corei3 4GBメモリで 35,780円。悪くはない。
で、6/25 に申し込んだが、その後、WiMaxの申し込み手続きが終わらないと購入手続きが進まなくってパソコンを入手できたのは 7/7 だった。
7/8 早朝にかけて Windows7 Ultimate Edition (64bit)をインストールした。
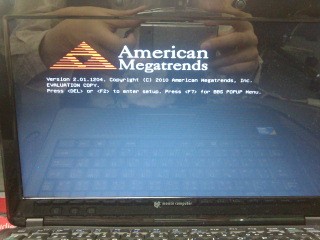
さて、このパソコン、起動すると intel のロゴがポツーンと出る。
しかし、僕はBIOS起動画面の方が好きなので、BIOS の設定を変えて「Quiet Boot」を disableにした。
すると、American Megatrands Inc. の BIOS の起動画面が表示される。
・・・・? Evaluation Copy? ライセンス的に大丈夫か?
一応マウスコンピューターのサポートに問い合わせたが、「弊社独自の BIOS なので問題ありません」との回答。いや、独自って言っているけどしっかり AMI のロゴが出ているのですけど。まぁ、問題を理解していたらこんな回答しないわな・・・ってわけでそれ以上追及はしていません。
さて、この 「Evaluation Copy」 のBIOS はマウスコンピューターが再配布していいものだったのだろうか?
なお、Quiet boot を disable にしている場合、再起動を行うと
BIOS のロゴを表示した時点で停止します。Quiet Boot を enable にすると発生しませんでした。
入手できたのが 7/7 だったので機械名は「TANABATA」です。
Float を主キーにしてはいけません。
2011年2月8日 コンピュータ「今の時代、基本的に、SQL Serverとかで float は使うべきではない。」(http://10395.diarynote.jp/200909072116364066/ )を書いた直後くらいに
「SQLServer Float Primary Key」での検索でアクセスがあった。
トラぶりそうだし面白そうだとおもいつつ、1年半ほど放置していたが、実験してみることにした。
SQL Server 2008 で試しました。
「SQLServer Float Primary Key」での検索でアクセスがあった。
トラぶりそうだし面白そうだとおもいつつ、1年半ほど放置していたが、実験してみることにした。
SQL Server 2008 で試しました。
CREATE TABLE FloatKeyTable(
FloatKey FLOAT CONSTRAINT PK_FloatKeyTable PRIMARY KEY
, Description NVARCHAR(50)
)
コマンドは正常に完了しました。
INSERT INTO FloatKeyTable(
FloatKey
, Description)
VALUES(8,’8’)
(1 行処理されました)
INSERT INTO FloatKeyTable(
FloatKey
, Description)
VALUES(8,’8’)
メッセージ 2627、レベル 14、状態 1、行 1
制約 ’PK_FloatKeyTable’ の PRIMARY KEY 違反。オブジェクト ’dbo.FloatKeyTable’ には重複したキーを挿入できません。
ステートメントは終了されました。
INSERT INTO FloatKeyTable(
FloatKey
, Description)
VALUES(
(CAST(0.1 AS FLOAT) + CAST(0.7 AS FLOAT)) * 10
, ’(CAST(0.1 AS FLOAT) + CAST(0.7 AS FLOAT)) * 10’)
(1 行処理されました)
INSERT INTO FloatKeyTable(
FloatKey
, Description)
VALUES(
(CAST(0.1 AS FLOAT) + CAST(0.7 AS FLOAT)) * 10
, ’(CAST(0.1 AS FLOAT) + CAST(0.7 AS FLOAT)) * 10’)
メッセージ 2627、レベル 14、状態 1、行 1
制約 ’PK_FloatKeyTable’ の PRIMARY KEY 違反。オブジェクト ’dbo.FloatKeyTable’ には重複したキーを挿入できません。
ステートメントは終了されました。
SELECT * FROM FloatKeyTable
FloatKey Description
---------------------- --------------------------------------------------
8 (CAST(0.1 AS FLOAT) + CAST(0.7 AS FLOAT)) * 10
8 8
(2 行処理されました)
SELECT * FROM FloatKeyTable
WHERE
FloatKey = 8
FloatKey Description
---------------------- --------------------------------------------------
8 8
(1 行処理されました)
SELECT * FROM FloatKeyTable
WHERE
FloatKey = (CAST(0.1 AS FLOAT) + CAST(0.7 AS FLOAT)) * 10
FloatKey Description
---------------------- --------------------------------------------------
8 (CAST(0.1 AS FLOAT) + CAST(0.7 AS FLOAT)) * 10
(1 行処理されました)
DELETE FROM FloatKeyTable WHERE FloatKey = 8
(1 行処理されました)
SELECT * FROM FloatKeyTable
FloatKey Description
---------------------- --------------------------------------------------
8 (CAST(0.1 AS FLOAT) + CAST(0.7 AS FLOAT)) * 10
(1 行処理されました)
新 SQL Server で時間を切り捨てる
2010年8月27日 コンピュータ コメント (2)今、横浜では 「Microsoft Tech Ed 2010 Japan」 が行われています。
最下層の屑技術者たる僕はそういうのにもいけず、
絶対に不可能な日程の仕事で、
欝が入ってますます効率が落ちている状態です。
そんなわけで逃避行動。
「SQL Server で時間を切り捨てる。」http://10395.diarynote.jp/200606080926140000/
はアクセスが多いです。
現時点で「sqlserver trunc 日付」でググるとトップに来るし。
まぁ、ほとんどの日本語のページが
として
という方法を示しているというある意味憂うべき状態だからなぁ。
・・・とはつつ、SQL Server のDatetime型を float として利用するのも問題が無いとはいえないんだけど。内部の実装に依存していることだから。
もちろん、SQL Server 2008 での基本且つ最良の方法である、
というのは結構あるが。
====================================
余談(本題はその後)
僕はあたりまえだと思うのだが
「あたりまえ」過ぎるのか、
「どんな場面でも通用する万能のルールではない」のか
あんまし SQL 作るときの注意点として挙げられていないような気がすることとして、
がある。
(2010年9月8日:「日付型」を「日時型」に訂正。本質的には日付型も同じ話だが下記の例は日時型なので。)
なので、
条件式に
とかせずに
とする。(もちろん、’2010/8/28’にすればいいのだが。)
は論外。ダメ!絶対!! http://10395.diarynote.jp/201004261843122549/
=========================================================
さて、本題。
「SQLServer Trunc」あたりで日本語以外を含めてググると
「How to truncate a datetime in SQL Server」
http://stackoverflow.com/questions/923295/how-to-truncate-a-datetime-in-sql-server
なるページがひっかかる。
このページの「The fast way:」(注参照)は「SQL Server で時間を切り捨てる。」http://10395.diarynote.jp/200606080926140000/ と同じ方法だが、
「The correct way:」は僕の知らなかった方法で、且つ「文字列にして切り取り」とも異なる方法であり、日本語のページでは見かけたことが無い方法だった。
を実行すると
となる。
もっとも、この方法、整数を datetime型に暗黙にキャストしているので、float にキャストしているのと大差ないともいえる。
同じサイトで別のページを探すとこんなのがひっかかった。
「Best approach to remove time part of datetime in SQL Server」
http://stackoverflow.com/questions/1177449/best-approach-to-remove-time-part-of-datetime-in-sql-server
似てはいるが、引数の順序が違う。
を実行すると
これも、0 に対する datetime 型への暗黙のCast に依存している。
で
暗黙のキャストを嫌って変えるとたとえばこうなるか。
SQL Server 2008 では date型にキャストすればいいので、
こんなことをする必要はないが、
この方法のおもしろいところは
日単位のみではなく、
年月、時、分、秒 でも使えるところである。
(http://stackoverflow.com/questions/85373/floor-a-date-in-sql-server )
特に年月に関しては有用だと思われる。
切り捨てなので、四捨五入(?)は半分引いて切り捨てて1足せばいいかな。
半分足して切り捨てればいい。
ここのサイトは勝手に全角化されたりするので、コードのサンプルは以下からコピーしてください。(2011年2月3日リンク修正)
http://kazamai7610.wordpress.com/2010/08/26/%e3%80%8c%e6%96%b0%e3%80%80sql-server-%e3%81%a7%e6%99%82%e9%96%93%e3%82%92%e5%88%87%e3%82%8a%e6%8d%a8%e3%81%a6%e3%82%8b%e3%80%8d%e3%81%ae%e3%82%b5%e3%83%b3%e3%83%97%e3%83%ab%e3%82%b3%e3%83%bc%e3%83%89/
2011年2月3日追記:
注:
「The fast way:」とあるが、コメントや他のページの情報では「The Correct way:」の方が速いようである。浮動小数点演算よりも整数演算のみの方が速いということらしい。
最下層の屑技術者たる僕はそういうのにもいけず、
絶対に不可能な日程の仕事で、
欝が入ってますます効率が落ちている状態です。
そんなわけで逃避行動。
「SQL Server で時間を切り捨てる。」http://10395.diarynote.jp/200606080926140000/
はアクセスが多いです。
現時点で「sqlserver trunc 日付」でググるとトップに来るし。
まぁ、ほとんどの日本語のページが
「日時から日付だけを取り出す」方法
として
「文字列にして切り取る」
という方法を示しているというある意味憂うべき状態だからなぁ。
・・・とはつつ、SQL Server のDatetime型を float として利用するのも問題が無いとはいえないんだけど。内部の実装に依存していることだから。
もちろん、SQL Server 2008 での基本且つ最良の方法である、
「SQL Server 2008 では date型へキャストする」 SELECT CAST(GETDATE() AS DATE)
というのは結構あるが。
====================================
余談(本題はその後)
僕はあたりまえだと思うのだが
「あたりまえ」過ぎるのか、
「どんな場面でも通用する万能のルールではない」のか
あんまし SQL 作るときの注意点として挙げられていないような気がすることとして、
SQL の条件式(WHERE句)で
・インデックスを活かすために列に対して演算やキャスト(暗黙のキャストも含む)は避けておく。
・文字列の比較は数値の比較に比べて遅い。日時型は数値の類型と考えられるので
文字列の比較は日時型に比べて遅い。さらに文字列のparse は遅いので文字列を日時にキャストする処理は遅い。
がある。
(2010年9月8日:「日付型」を「日時型」に訂正。本質的には日付型も同じ話だが下記の例は日時型なので。)
なので、
条件式に
SELECT * from test1 WHERE CONVERT(nvarchar(10),dt1,111) = ’2010/08/27’
SELECT * from test1 WHERE CAST(floor(CAST(dt1 AS FLOAT)) AS DATETIME) = CAST(’2010/8/27’ AS DATETIME)
DECLARE @dt AS DATETIME
SET @dt = CAST(’2010/8/27’ AS DATETIME)
SELECT * from test1 WHERE (dt1 >= @dt) AND (dateadd(day,-1,dt1) < @dt)
とかせずに
SELECT * from test1 WHERE(dt1 >= CAST(’2010/8/27’ AS DATETIME)) AND (dt1 < dateadd(day,1,CAST(’2010/8/27’ AS DATETIME)))
とする。(もちろん、’2010/8/28’にすればいいのだが。)
SELECT * from test1 WHERE dt1 between CAST(’2010/8/27’ AS DATETIME) AND CAST(’2010/8/27 23:59:59.999’ AS DATETIME
は論外。ダメ!絶対!! http://10395.diarynote.jp/201004261843122549/
=========================================================
さて、本題。
「SQLServer Trunc」あたりで日本語以外を含めてググると
「How to truncate a datetime in SQL Server」
http://stackoverflow.com/questions/923295/how-to-truncate-a-datetime-in-sql-server
なるページがひっかかる。
このページの「The fast way:」(注参照)は「SQL Server で時間を切り捨てる。」http://10395.diarynote.jp/200606080926140000/ と同じ方法だが、
「The correct way:」は僕の知らなかった方法で、且つ「文字列にして切り取り」とも異なる方法であり、日本語のページでは見かけたことが無い方法だった。
SELECT dateadd(DAY,0,DATEDIFF(DAY,0,getdate()))
を実行すると
-----------------------
2010-08-27 00:00:00.000
(1 行処理されました)
となる。
もっとも、この方法、整数を datetime型に暗黙にキャストしているので、float にキャストしているのと大差ないともいえる。
同じサイトで別のページを探すとこんなのがひっかかった。
「Best approach to remove time part of datetime in SQL Server」
http://stackoverflow.com/questions/1177449/best-approach-to-remove-time-part-of-datetime-in-sql-server
似てはいるが、引数の順序が違う。
SELECT dateadd(DAY,DATEDIFF(DAY,0,getdate()),0)
を実行すると
-----------------------
2010-08-27 00:00:00.000
(1 行処理されました)
これも、0 に対する datetime 型への暗黙のCast に依存している。
SELECT CAST(0 as datetime)
で
-----------------------
1900-01-01 00:00:00.000
暗黙のキャストを嫌って変えるとたとえばこうなるか。
DECLARE @dtBase as datetime
SET @dtBase = CAST(’2010/1/1’ as datetime)
SELECT dateadd(DAY,DATEDIFF(DAY,@dtBase,getdate()),@dtBase)
SQL Server 2008 では date型にキャストすればいいので、
こんなことをする必要はないが、
この方法のおもしろいところは
日単位のみではなく、
年月、時、分、秒 でも使えるところである。
(http://stackoverflow.com/questions/85373/floor-a-date-in-sql-server )
DECLARE @dtBase as datetime
SET @dtBase = CAST(’2010/1/1’ as datetime)
SELECT ’YEAR:’,dateadd(YEAR,DATEDIFF(YEAR,@dtBase,getdate()),@dtBase)
UNION ALL SELECT ’MONTH:’,dateadd(MONTH,DATEDIFF(MONTH,@dtBase,getdate()),@dtBase)
UNION ALL SELECT ’DAY:’,dateadd(DAY,DATEDIFF(DAY,@dtBase,getdate()),@dtBase)
UNION ALL SELECT ’HOUR:’,dateadd(HOUR,DATEDIFF(HOUR,@dtBase,getdate()),@dtBase)
UNION ALL SELECT ’MINUTE:’,dateadd(MINUTE,DATEDIFF(MINUTE,@dtBase,getdate()),@dtBase)
UNION ALL SELECT ’SECOND:’,dateadd(SECOND,DATEDIFF(SECOND,@dtBase,getdate()),@dtBase)
UNION ALL SELECT ’:’,GETDATE()
------- -----------------------
YEAR: 2010-01-01 00:00:00.000
MONTH: 2010-08-01 00:00:00.000
DAY: 2010-08-27 00:00:00.000
HOUR: 2010-08-27 08:00:00.000
MINUTE: 2010-08-27 08:32:00.000
SECOND: 2010-08-27 08:32:23.000
: 2010-08-27 08:32:23.843
特に年月に関しては有用だと思われる。
切り捨てなので、四捨五入(?)は
半分足して切り捨てればいい。
DECLARE @dtBase as datetime
SET @dtBase = CAST(’2010/1/1’ as datetime)
DECLARE @dt1 datetime
DECLARE @dt2 datetime
SET @dt1= CAST(’2010/8/27 08:16:29’ as datetime)
SET @dt2= CAST(’2010/8/27 08:16:30’ as datetime)
SELECT DATEADD(MINUTE,DATEDIFF(MINUTE,@dtBase,DATEADD(SECOND,30,@dt1)),@dtBase)
SELECT DATEADD(MINUTE,DATEDIFF(MINUTE,@dtBase,DATEADD(SECOND,30,@dt2)),@dtBase)
ここのサイトは勝手に全角化されたりするので、コードのサンプルは以下からコピーしてください。(2011年2月3日リンク修正)
http://kazamai7610.wordpress.com/2010/08/26/%e3%80%8c%e6%96%b0%e3%80%80sql-server-%e3%81%a7%e6%99%82%e9%96%93%e3%82%92%e5%88%87%e3%82%8a%e6%8d%a8%e3%81%a6%e3%82%8b%e3%80%8d%e3%81%ae%e3%82%b5%e3%83%b3%e3%83%97%e3%83%ab%e3%82%b3%e3%83%bc%e3%83%89/
2011年2月3日追記:
注:
「The fast way:」とあるが、コメントや他のページの情報では「The Correct way:」の方が速いようである。浮動小数点演算よりも整数演算のみの方が速いということらしい。
「休日分散化」反対!
2010年8月17日 コンピュータ今年は今までほど「サマータイム導入」の話を聞かない気がする。(http://10395.diarynote.jp/200405260620500000)
どっかテストをやってたところもやめたし、韓国も導入を見送りにした。
時計の針をを動かさずにやるのだったら反対しないけど。
(中国の、「国土全体で単一の基準時間」ってのもいい考えだとおもうし。)
でも、代わりに厄介なのが登場。
「休日分散化法案」( http://www.mlit.go.jp/kankocho/iinkai/suishinhonbu/pdf/kyuka_wt_02_05.pdf )
まぁ、「サマータイム」ほど強く反対するわけではないけど。
単に「嫌だ」ってレベルです。
その祝日の経緯を無視して動かすのはどうかと。
実験のため試験的に休日をふやしてみるってのならいいかも。
全国的に「南関東基準になる(南関東以外は休めない)」となるとおもうけどなぁ。。。
・サマータイム 機能面で国家的危機
・休日分散化 日本の文化的危機
ってところか。
どっかテストをやってたところもやめたし、韓国も導入を見送りにした。
時計の針をを動かさずにやるのだったら反対しないけど。
(中国の、「国土全体で単一の基準時間」ってのもいい考えだとおもうし。)
でも、代わりに厄介なのが登場。
「休日分散化法案」( http://www.mlit.go.jp/kankocho/iinkai/suishinhonbu/pdf/kyuka_wt_02_05.pdf )
まぁ、「サマータイム」ほど強く反対するわけではないけど。
単に「嫌だ」ってレベルです。
その祝日の経緯を無視して動かすのはどうかと。
実験のため試験的に休日をふやしてみるってのならいいかも。
全国的に「南関東基準になる(南関東以外は休めない)」となるとおもうけどなぁ。。。
・サマータイム 機能面で国家的危機
・休日分散化 日本の文化的危機
ってところか。
ここの日記、コンピュータのコードとか書きにくいので
コード書き用に別荘作りました。
http://kazamai-naruto.spaces.live.com/
ただ、これアクセスログが見れないんでどっかいい場所がないか探り中。
【xyzzy で階乗を求める】
http://kazamai-naruto.spaces.live.com/blog/cns!17D3E5D8390D408!236.entry
【「子どもが二人居て、少なくとも一人は火曜日生まれの男の子の場合に、もう一人も男の子である確率」を求める SQL】
http://kazamai-naruto.spaces.live.com/blog/cns!17D3E5D8390D408!246.entry
【.NET Framework での「クラスとメソッドの名前を使ってのメソッドの実行」】
http://kazamai-naruto.spaces.live.com/blog/cns!17D3E5D8390D408!248.entry
あと、ついでにつぶやいてます。
http://twitter.com/KAZAMAI_NaruTo
コード書き用に別荘作りました。
http://kazamai-naruto.spaces.live.com/
ただ、これアクセスログが見れないんでどっかいい場所がないか探り中。
【xyzzy で階乗を求める】
http://kazamai-naruto.spaces.live.com/blog/cns!17D3E5D8390D408!236.entry
【「子どもが二人居て、少なくとも一人は火曜日生まれの男の子の場合に、もう一人も男の子である確率」を求める SQL】
http://kazamai-naruto.spaces.live.com/blog/cns!17D3E5D8390D408!246.entry
【.NET Framework での「クラスとメソッドの名前を使ってのメソッドの実行」】
http://kazamai-naruto.spaces.live.com/blog/cns!17D3E5D8390D408!248.entry
あと、ついでにつぶやいてます。
http://twitter.com/KAZAMAI_NaruTo
